Hi~ I am Jingyuan Liu, a Machine Learning Engineer at Adobe Lightroom working with Jimei Yang and Simon Chen. I received a M.S. in Data Science at Harvard University and a B.S. in Computer Science at Fudan University. Previously, I was a research assistant at Upenn GRASP lab advised by Prof. Jianbo Shi and Harvard EconCS lab advised by Prof. David C.Parkes.
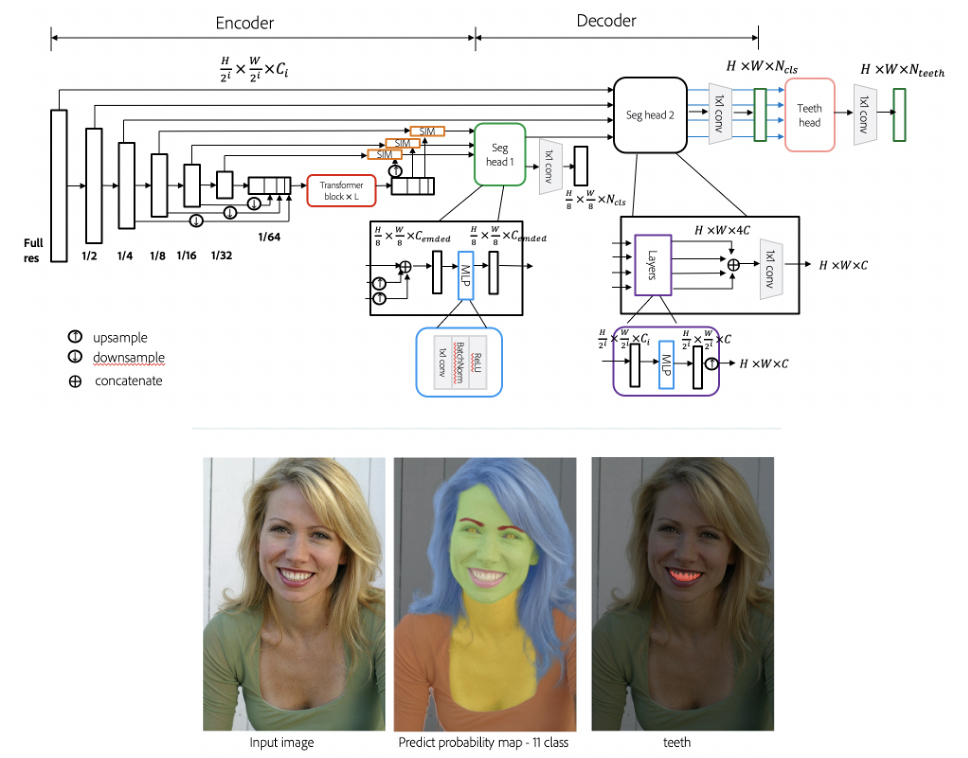
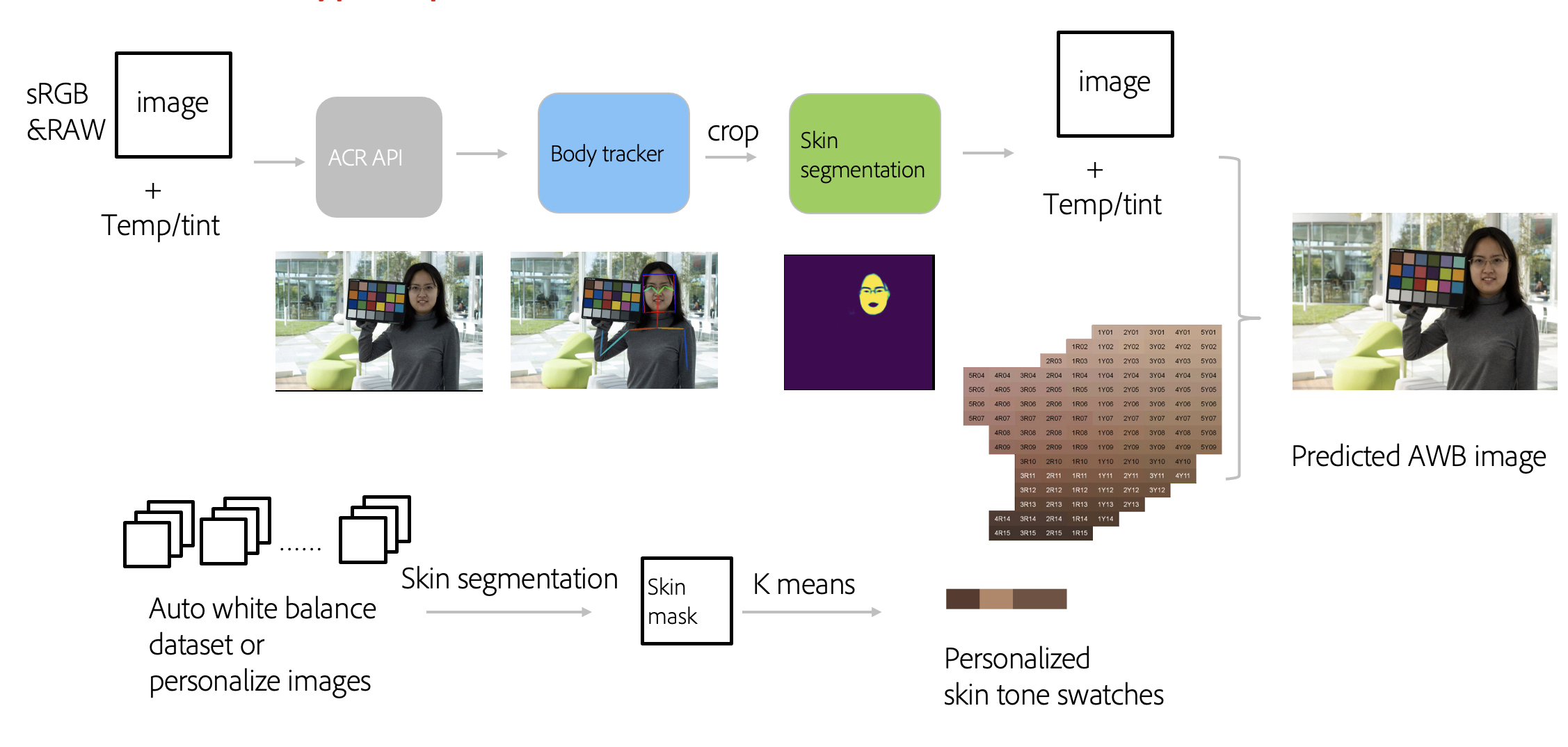
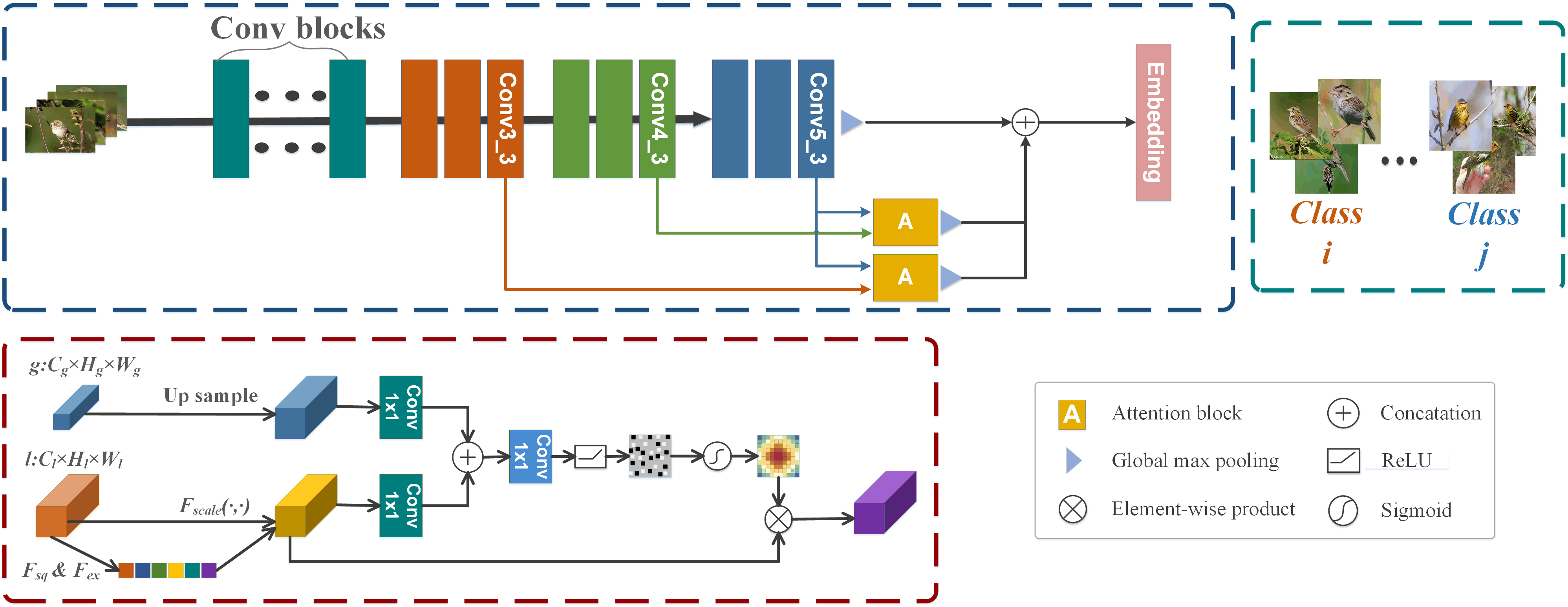
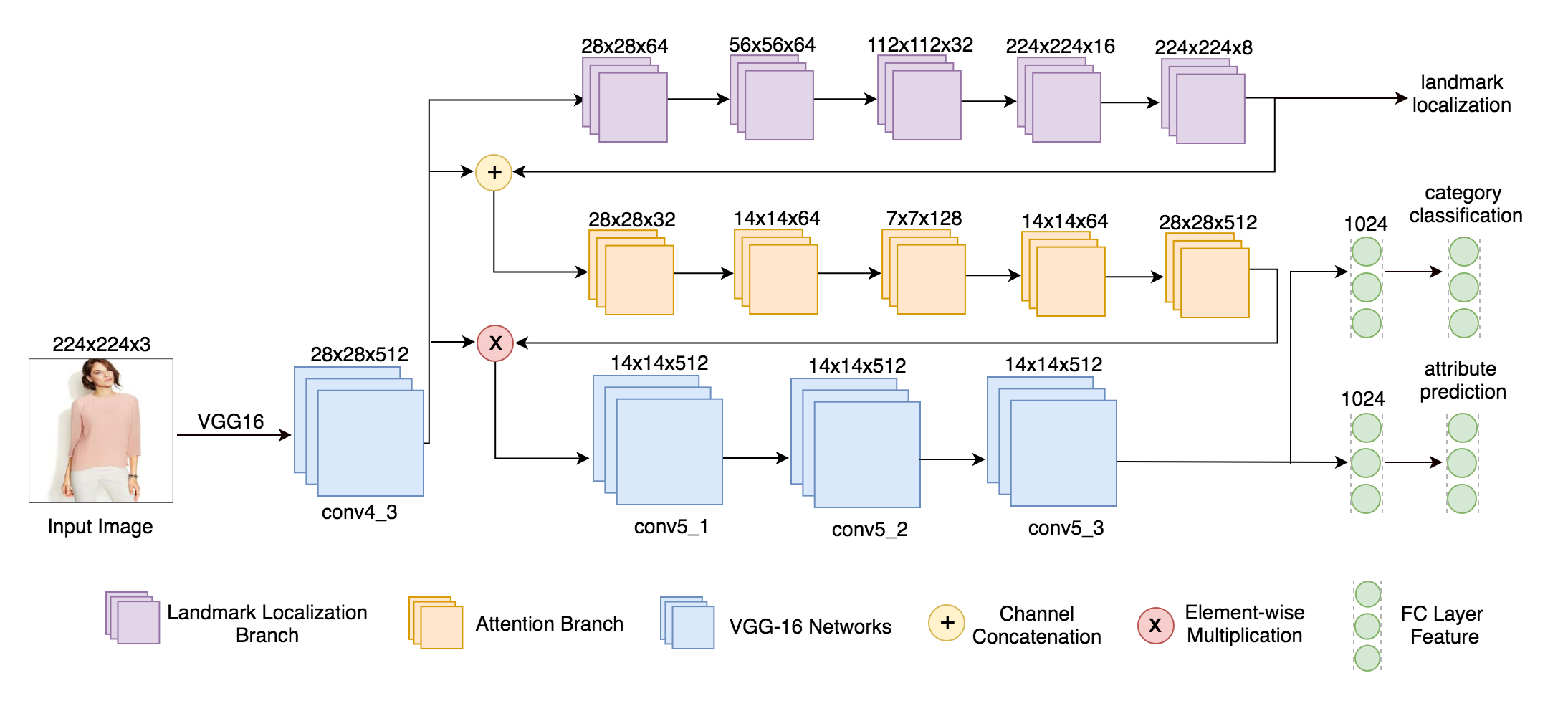
My work focused on semantic segmentation and auto white balance. I am particularly interested in the intersection between language and vision. Recently, I am working on 3D depth estimation and AI photo critique.
Email: jingyliu@adobe.com / CV / Google Scholar / Github / Linkedin